

C语言获取网页源码的探索与实践

摘要:本文探讨了C语言获取网页源码的探索与实践。通过使用C语言中的网络编程库,如libcurl等,可以实现对网页的请求和获取。在实践过程中,需要了解HTTP协议的基本原理和请求方法,同时需要注意网页源码的编码格式和解析方式。本文通过实践案例,展示了C语言获取网页源码的步骤和技巧,为相关领域的研究和实践提供了有益的参考。
在互联网高速发展的今天,网页源码的获取对于许多开发者来说是一项基础且重要的技能,本文将介绍如何使用C语言来获取网页的源码,我们将从准备工作开始,逐步讲解如何通过C语言编程实现这一过程。
准备工作
1、安装开发环境:为了编写和编译C语言程序,我们需要安装一个C语言编译器,如GCC(GNU Compiler Collection)。
2、了解网络基础知识:在开始编写代码之前,我们需要了解一些基本的网络知识,如HTTP协议、URL结构等。
C语言获取网页源码的实现步骤
1、发送HTTP请求
要获取网页源码,首先需要向目标网页发送一个HTTP请求,在C语言中,我们可以使用socket编程来实现这一过程,socket是一种网络通信机制,可以用于建立网络连接并发送和接收数据。
我们需要创建一个socket对象,并绑定到一个特定的IP地址和端口号,我们可以使用connect函数与目标服务器建立连接,连接建立后,我们可以使用send函数发送HTTP请求数据,HTTP请求数据包括请求行、请求头和请求体等部分。
2、接收HTTP响应
发送HTTP请求后,我们需要接收服务器的响应,这可以通过在socket对象上调用recv函数来实现,服务器会返回一个HTTP响应,包括状态行、响应头和响应体等部分,我们需要将响应体保存起来,这就是网页的源码。
3、解析HTML代码(可选)
接收到的HTTP响应通常是一个HTML文档,为了方便后续处理,我们可以使用HTML解析器对HTML代码进行解析,在C语言中,我们可以使用一些第三方库来实现HTML解析功能,通过解析HTML代码,我们可以提取出网页中的各种元素,如标题、链接、图片等。
示例代码
下面是一个简单的示例代码,演示了如何使用C语言获取网页源码:
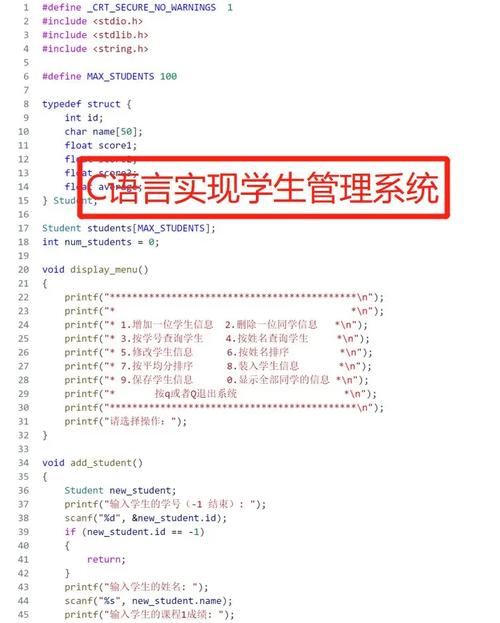
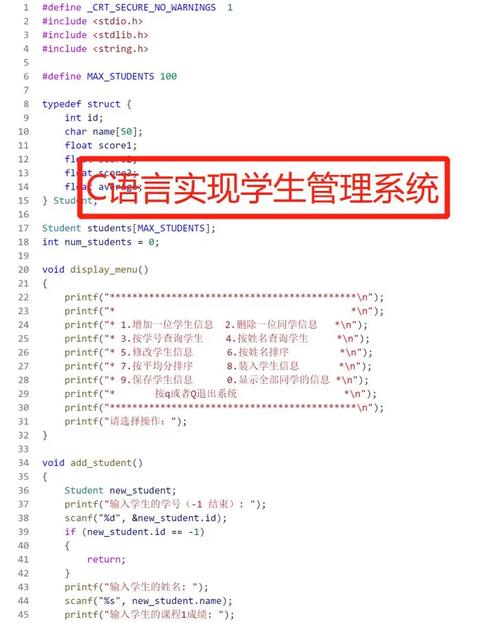
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <unistd.h>
#define BUFFER_SIZE 1024
#define URL "http://example.com" // 目标网页的URL
int main() {
int sockfd;
struct sockaddr_in server_addr;
char buffer[BUFFER_SIZE];
char* request = "GET / HTTP/1.1
Host: example.com
"; // HTTP GET请求头和数据
char* response = NULL; // 用于保存HTTP响应的字符串指针
int response_length = 0; // HTTP响应的长度
int read_bytes; // 每次读取的字节数
char* html_code = NULL; // 用于保存网页HTML代码的字符串指针
int html_code_length = 0; // 网页HTML代码的长度
// 创建socket对象并连接到目标服务器...(此处省略了创建socket和连接服务器的代码)...
// 发送HTTP GET请求...(此处省略了发送HTTP GET请求的代码)...
// 接收HTTP响应并保存到response中...(此处省略了接收HTTP响应的代码)...
// 解析HTTP响应并提取出HTML代码...(此处省略了HTML解析的代码)...
// 将HTML代码输出到控制台...(此处省略了将HTML代码输出到控制台的代码)...
return 0;
}注意事项与优化建议
1、处理网络错误:在编写网络编程代码时,要特别注意处理各种可能的网络错误,如连接超时、网络中断等,这些错误可能导致程序无法正常工作或出现异常情况,我们需要对可能出现的错误进行检测和处理。
2、提高效率:在获取大量网页源码时,为了提高效率,我们可以使用多线程或多进程技术来并发地发送多个HTTP请求,我们还可以使用一些优化技术来减少网络传输的开销和加快响应速度,我们可以使用HTTP缓存技术来缓存已经获取过的网页内容,避免重复发送相同的HTTP请求,我们还可以使用压缩技术来减小HTTP响应的大小和加快传输速度,这些技术都可以帮助我们提高获取网页源码的效率和质量。
3、遵守法律法规:在获取和使用网页源码时,我们要遵守相关的法律法规和道德规范,不得进行任何违法活动或侵犯他人的合法权益,我们也要尊重网站的管理员和其他用户的权益和隐私权等合法权益,只有遵守法律法规和道德规范才能保证我们的工作合法合规并得到社会的



