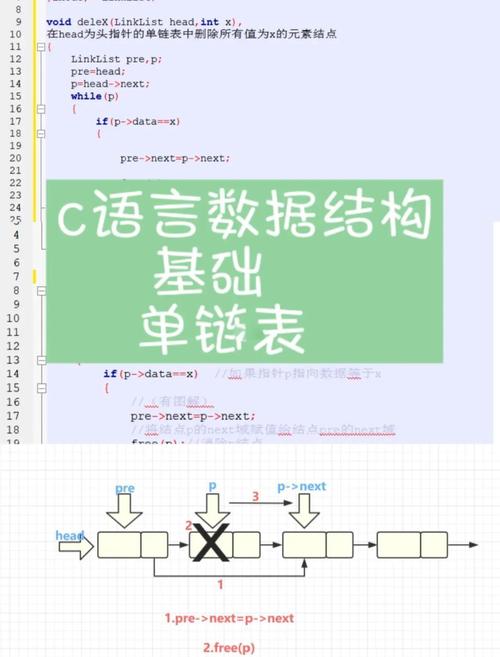
C语言实现链表结构详解

C语言实现链表结构详解:链表是一种动态数据结构,由一系列节点组成,每个节点包含数据元素和指向下一个节点的指针。在C语言中,可以通过结构体和指针实现链表。首先定义节点结构,包含数据域和指针域;然后创建头节点,作为链表的起始点;接着根据需求进行节点的增删查改等操作。链表有单向链表和双向链表之分,各有其特点和适用场景。通过C语言实现链表结构,可以灵活地处理大量数据,是编程中的重要技能。
在计算机编程中,链表是一种常见的数据结构,它以节点为单位进行存储,每个节点包含数据域和指向下一个节点的指针域,链表具有动态分配内存空间、插入和删除操作方便等优点,因此在许多应用场景中都有广泛的应用,本文将详细介绍如何使用C语言实现链表结构。
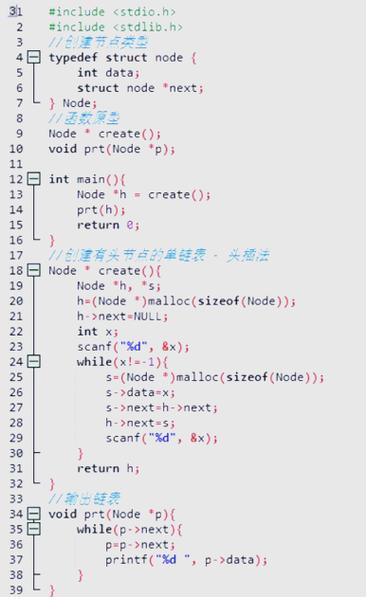
链表的基本概念
链表是一种线性数据结构,它由一系列节点组成,每个节点包含数据域和指向下一个节点的指针域,与数组不同,链表的存储空间是动态分配的,每个节点可以单独分配内存空间,链表的节点通常由两部分组成:数据域和指针域,数据域用于存储实际的数据,而指针域则用于指向下一个节点的地址。
C语言实现链表结构
在C语言中,我们可以使用结构体(struct)来定义链表的节点,下面是一个简单的示例代码,展示如何使用C语言实现一个简单的链表结构:
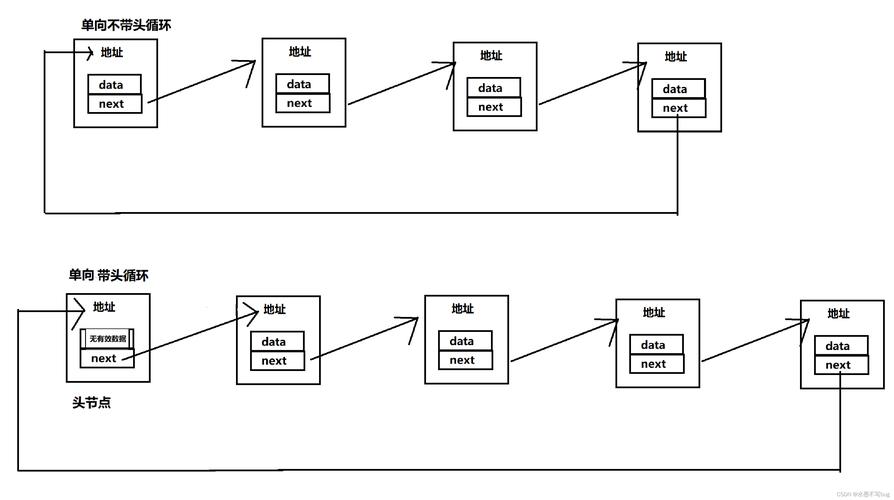
#include <stdio.h>
#include <stdlib.h>
// 定义链表节点结构体
typedef struct Node {
int data; // 数据域,存储整型数据
struct Node* next; // 指针域,指向下一个节点的指针
} Node;
// 创建新节点的函数
Node* createNode(int data) {
Node* newNode = (Node*)malloc(sizeof(Node)); // 动态分配内存空间
if (newNode == NULL) {
printf("Memory allocation failed!\n");
exit(1); // 内存分配失败时退出程序
}
newNode->data = data; // 设置节点数据
newNode->next = NULL; // 设置指针域为NULL,表示该节点是链表的最后一个节点
return newNode; // 返回新创建的节点指针
}
// 在链表末尾添加节点的函数
void appendNode(Node** head, int data) {
Node* newNode = createNode(data); // 创建新节点
if (*head == NULL) { // 如果链表为空,则将新节点设置为头节点
*head = newNode;
} else { // 否则,找到链表的最后一个节点,并将其指针域指向新节点
Node* temp = *head;
while (temp->next != NULL) { // 遍历链表,找到最后一个节点
temp = temp->next;
}
temp->next = newNode; // 将最后一个节点的指针域指向新节点
}
}在上面的代码中,我们首先定义了一个名为Node的结构体,用于表示链表的节点,该结构体包含两个成员:data用于存储实际的数据,next用于指向下一个节点的指针,我们定义了两个函数:createNode用于创建新的节点,appendNode用于在链表末尾添加新的节点,在appendNode函数中,我们首先调用createNode函数创建一个新的节点,然后判断链表是否为空,如果为空,则将新节点设置为头节点;否则,遍历链表找到最后一个节点,并将其指针域指向新节点,这样,我们就实现了在链表末尾添加节点的功能。
通过上述示例代码,我们了解了如何使用C语言实现链表结构,链表作为一种常见的数据结构,具有动态分配内存空间、插入和删除操作方便等优点,在实际应用中,我们可以根据具体的需求来设计和实现不同的链表结构,可以根据需要定义不同的节点结构、实现不同的插入和删除操作等,随着计算机科学的发展和应用的不断拓展,链表结构也将不断发展和完善,以适应更多的应用场景和需求,掌握链表结构的基本原理和实现方法对于提高编程能力和解决实际问题具有重要意义。